Technical SEO
The Professional's Guide to SEO: Technical actions to improve search results
There are competing definitions for what technical SEO actually includes. Some narrow it down as far as possible — to technical concepts specific to SEO, such as directives, robots.txt, crawl paths, and so on. This is technical as in "technical language" — meaning, in essence, just very specific.

Others broaden their definition of technical SEO to include any SEO activity that leverages even a basic technical understanding. You may have noticed, for example, how title tags and H1s appear in many "technical SEO" auditing tools.
Back in 2017, the late great Russ Jones suggested this definition:
Any sufficiently technical action undertaken with the intent to improve search results.
He illustrated that with this chart:
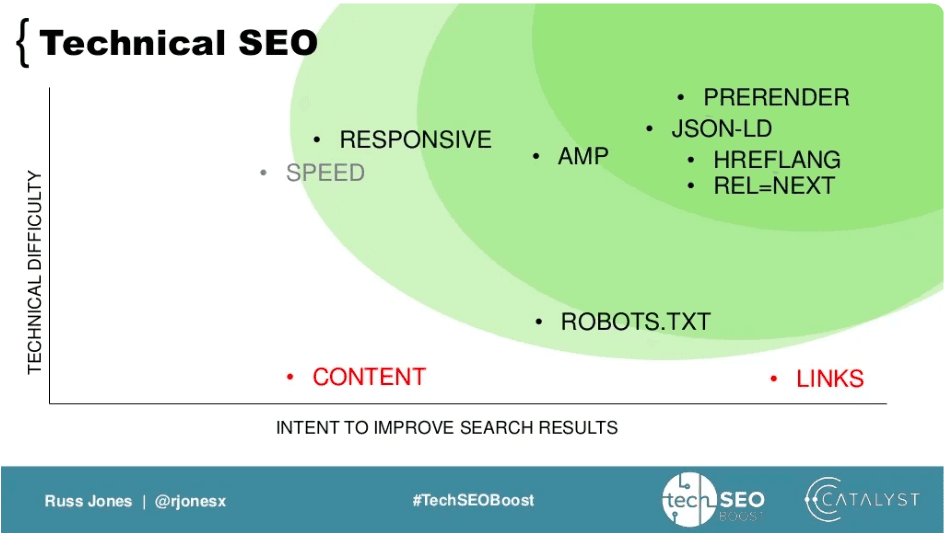
For Russ, the focus was on the action being technical, rather than the subject or expertise drawn upon.
In this chapter we'll take a little from all of these definitions. We'll cover:
The technical foundations to technical and non-technical SEO alike — PageRank, crawling and indexing, and rendering
SEOs' specialist technical knowledge — directives, hreflang, robots.txt, indexing APIs, and so on
Technical activities with SEO intent — performance, structured data, and SEO "on the edge"
We won't, on the other hand, cover the topics that are well covered by the Beginner's Guide to SEO and its equivalent chapter. If you want to read about how the web works, canonicalization, or basic performance optimization techniques, you can go check that out here.
The technical foundations of SEO
This first section speaks to part one of Russ’s triumvirate — how SEO and Google actually work, and the (mostly) technical underpinnings that you’ll need to make sense of the rest. For the purpose of this guide, we’ll focus on links, indexing, and rendering, although for a more “first principles” introduction to how search engines work, you can check out the Beginner’s Guide to SEO chapters (1, 2) as useful pre-reading.
Links & PageRank
Links. Everybody loves them, but how do they work?
Back in the late 90s, links were a much larger part of how people navigated the web, perhaps from portals like this one:

Google’s core innovation was to work out a way of using these links as a proxy for popularity. They theorized that if a very popular page had twenty links on it, then some fraction (perhaps a twentieth) of the traffic from that page would pass on to the pages it linked to. Which would then pass on their traffic in a similar way, and so on. Through this system, they aimed to calculate the chance that a person browsing the web was on any given page — just based on how prominently it featured in its web of links. This system was called PageRank.
Of course, there’s a bit more to it than that. The first major caveat is that there is a chance that a user browsing a page will simply hit a bookmark or otherwise request a random page, rather than clicking a link. Mathematically, this stops the PageRank of all pages converging on 0 or 1. This dampening factor, suggested in the original PageRank paper of 1998 as 15%, underpins a huge amount of modern SEO best practice.
Let’s see how it looks in practice:
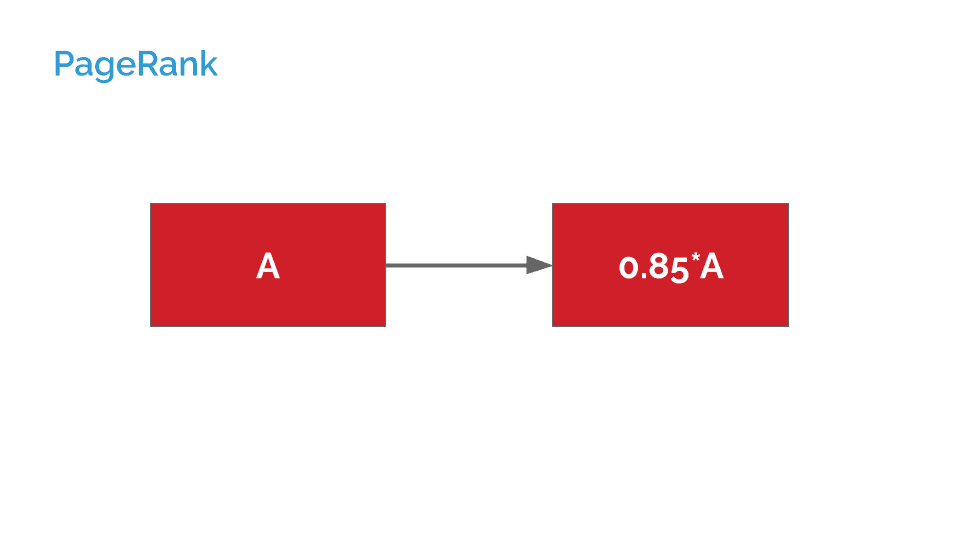
If we imagine that page A links to exactly one other page, that other page receives 0.85* A’s PageRank.
Under a basic system, if A instead linked to two pages, the amount passed on to each would be cut in half:
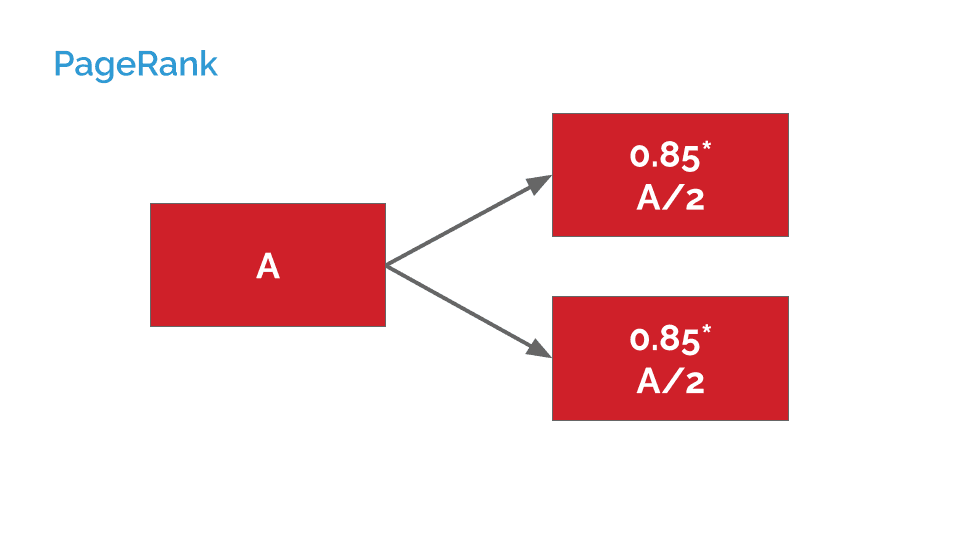
If, instead, A linked indirectly to a third page, this dampening factor would be applied twice:
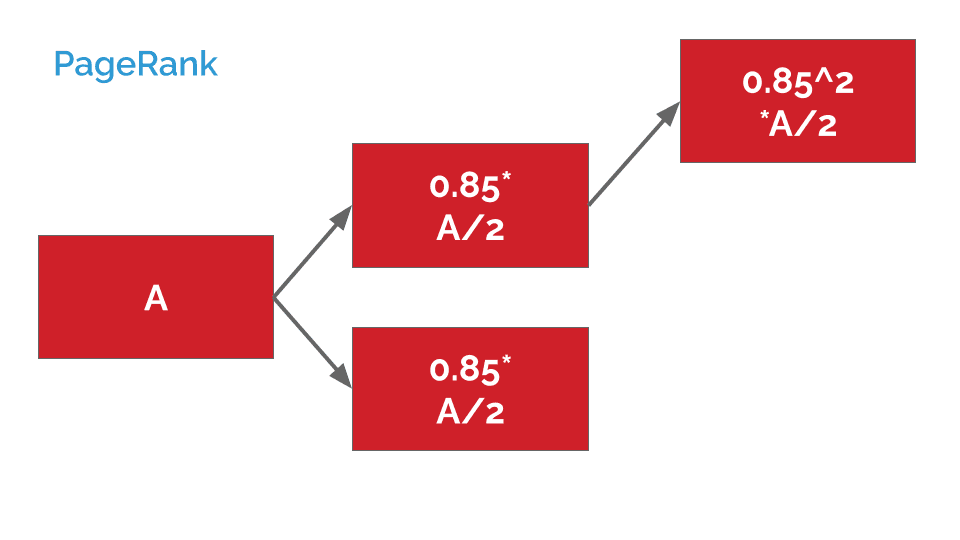
With 0.85*0.85, aka 0.85^2, working out at 0.7225.
You can quickly see how complex this can get. We're looking at examples where each page only links to one or two other pages, and don’t link back to each other.
However, from these simple examples, we can already take away a few fundamental lessons as technical SEOs:
Indirect links further dilute value. This applies to canonicals and redirects, too — a redirect is basically a page with exactly one link.
The more links a page has to other pages, the less value each of them is passing. This has implications for site structure and navigation — linking to a lot of pages besides the ones you care about is diluting the ones you care about. (Historically, nofollow links wouldn’t count towards this devaluing, but this hasn’t been the case for a long time.)
We're talking about pages, not sites or domains. Concepts like Domain Authority have merit because pages on a given site overwhelmingly link to each other, rather than externally, which creates clusters of authority. But there’s no inherent concept of a domain here.
These basic building blocks can help us to understand the reasoning behind a lot of SEO best practices, but there are a few more caveats and complications to introduce:
Reasonable surfer. If a page has two links, they won’t necessarily pass on the same equity - a link that is more likely to be clicked on will get a larger share.
Noindex = nofollow.
Noindex = nofollow
No, that isn’t a typo.
Remembering what we learned in the section above, there’s really very few good reasons to use "noindex, nofollow". Sure, you might want to exclude a thin or low-value page from the index, but do you want to prevent it from recycling PageRank into the rest of your site via internal linking? Of course not. To justify this tag, you get into extreme niche situations around pages that link to resources you don’t want Google to even know exist — in which case, wouldn't robots.txt be an easier solution?
However, it looks at first glance like there might be a good case for “noindex” (which is the same in effect as the more explicit “noindex,follow”). Perhaps you have a page you don’t want indexed, but it still links to other pages on your site, so you’d like to avoid a PageRank dead-end, right?
Wrong, unfortunately. A few years back, Google revealed that, although they hadn’t really noticed, it was an unintended consequence of their algorithm that noindex pages eventually become de facto nofollow, simply because they stop being crawled.
This has some implications for the attractiveness of the noindex directive, of course. Sometimes a solution like a canonical tag might help, but this isn’t always practical if the page doesn’t have a near-duplicate you want indexed. There are “have your cake and eat it” options, like obscuring the link with JavaScript (and then blocking the script in robots.txt), but this could be viewed as not strictly in line with Google’s Webmaster Guidelines.
So, in the end we have to avoid linking excessively to such pages — which may pose UX challenges. As a technical SEO, you have to weigh off these compromises.
Rendering
About that JavaScript you mentioned...
These days, Google claims to be able to parse JavaScript-reliant pages. That’s somewhat true, but there’s a couple of caveats:
Sometimes it doesn’t go very well
Other search engines & crawlers do it even worse
Rendering isn’t just for JavaScript though, and it’s a good concept to understand when working on even a simple site. Try contrasting what you see in the raw HTML source code of a page (Ctrl+U in Chrome) with the elements tab in Developer Tools (Ctrl+Shift+I in Chrome). The difference is that the former is raw HTML, and the latter is the rendered page. This difference can vary more from one site to the next, and is a common source of initially perplexing SEO issues.
There are some good tools out there to help you understand this distinction, but we particularly recommend the View Rendered Source Chrome extension.
How Googlebot renders your page (& why it may not)
Anyway, back to Googlebot.
Googlebot initially parses the raw HTML, which it especially uses for link discovery. After that a page goes into the render queue, where it waits maybe seconds or weeks to be rendered by, effectively, a Chrome browser, before being passed back to the processing stage and indexed.
So if your initial content doesn’t work without being rendered, perhaps due to JavaScript reliance, you’re delaying that initial link discovery. Which might be fine. The bigger issue is if the rendering doesn’t quite work.
Some examples of this can be due to:
Timing out before the page is finished rendering
Critical resources blocked in robots.txt
Poor parsing of JavaScript
You can use tools like Google Search Console and the Mobile Friendliness Test to see Googlebot in action. Usually it does a pretty good job, but again, this is a common source of SEO shenanigans.
Pre-rendering & dynamic rendering
Over the years, Google has advocated for various alternatives to relying on its own JavaScript parsing ability. Many SEOs working on JavaScript-reliant sites choose to circumvent the issue entirely with pre-rendering, but Google’s current favored solution is the so-called Dynamic Rendering. We’ll briefly look at each in turn.
Pre-rendering
The ideal compromise is to show search engines a plain HTML page they can understand, but show users your fancy JavaScript-fueled web app, right? Pre-rendering services and frameworks do exactly that, sometimes serving only bots a specific HTML version, or sometimes generating pre-rendered HTML versions for users and bots alike.
You may also see the phrase “server-side rendering” used, which is similar in that plain HTML is supplied to users, but differs in that the rendering is done on request, each time a user tries to access a page.
Dynamic rendering
Typically, "cloaking," the practice of showing users and Googlebot different content, has been something Google frowns upon and aims to penalize. However, exceptions have been made over the years for the purpose of handling JavaScript-dependent sites, and the latest such exception is dynamic rendering.
Dynamic rendering is simply Google’s term for the version of pre-rendering mentioned above that only serves pre-rendered pages to specific user agents, namely bots. Although many sites were doing this before Google’s 2018 acknowledgement of the tactic, by explicitly acknowledging it, Google is giving it legitimacy and reassuring users they won’t get punished. Bing has also explicitly acknowledged this method.
SEOs' specialist technical knowledge
So far, we’ve discussed the core functioning of SEO. This next section is a little different — rather than the technical details of how general SEO works, this section is about the technicalities of SEO as a discipline. Some of these are often talked about as their own discipline — such as international SEO or mobile SEO.
Specialist directives
Many of these specialist topics come about because of complications around PageRank that we learned about above, or about duplication, as covered in the Beginner’s Guide.
If you start out serving customers in the UK but then want to serve different content to British vs. Australian audiences, for example, how can you make sure that your new, second version carries some of the authority of the original page? How can you make sure that Google displays the right one?
There are various sanctioned special cases for duplication, including:
Internationalization, via rel="alternate" hreflang tags
Mobile, via rel="alternate" media tags (although a single, responsive page is much preferred in recent years!)
AMP, via rel="amphtml" tags
Server-side-rendered versions, via dynamic serving or historically via meta name="fragment" tags
What these tags do should not be confused with canonicalization. Indeed, best practice with regards to canonicalization varies from one case to the — international variants are considered to all be their own canonical variant, whereas for mobile variants one version is considered the canonical.
That said, there is some transfer of authority in these cases, as one would expect with a canonical tag (albeit maybe not to the same extent). Tom Anthony demonstrated this a few years ago while exposing a bug in Google’s sitemap submission process. His test showed that new domains linked by hreflang only to older, established domains could instantly appear in competitive search rankings.
Indexing & crawl budget
Larger websites often stand to benefit the most from strong technical SEO, precisely because of their size. Google says that sites of above one million pages, or with 10,000 pages updated on a daily basis, could expect to have issues around "crawl budget." (Although in reality, crawl budget issues will kick in at different scales depending on the authority, popularity, and freshness of your site, so this is an under-nuanced benchmark.) In addition, larger sites are likely to struggle more to concentrate their authority in key pages, due to complex site architectures or simply needing to simultaneously compete for a wide array of highly competitive search intents.
Starting with "crawl budget," though — this concept refers to the finite time that Google might allocate to crawl a given website. In some cases this may not be enough for the deeper or more obscure pages on a site to be crawled in a timely fashion, or perhaps at all. Such issues typically come up for one of a few reasons:
Facets, such as filtering/sorting parameters (example.com/shirt?&colour=yellow&size=large&page=230 etc.) resulting in an extremely high number of dynamically generated URLS
- User-generated URLs, especially
Search results pages
Listings pages, especially for job listings or classified adverts, where each new advert generates (at least) one new URL.
Comment sections and forums
This isn’t an exhaustive list, of course. These are just a few of the more common examples we've experienced.
SEOs have tools they can use to contain the number of URLs that Google might stumble upon, thereby wasting precious crawl budget. All of these tools have their compromises, however:
Robots.txt block or nofollow - creates a PageRank dead end, as we explored earlier in this chapter, preventing the recycling of any PageRank coming into the page, back to the rest of the site.
Noindex - also eventually creates a PageRank dead end.
Canonical tags - only applicable when Google will respect the page as a duplicate of an indexed page. Plus, the page will still be crawled, albeit perhaps less, so crawl budget gains may be minimal.
301 redirect - only applicable when users don’t need to access the redundant page, and ought to be accompanied by internal link cleanup
Ultimately, the best solution is to avoid creating too many of these redundant URLs in the first place.
Indexing tools
On the other hand, SEOs might also wish to make better use of their crawl budget by encouraging Google or other search engines to prioritize the URLs they have recently changed, recently added, or otherwise consider urgent.
Historically this generally meant prominent featuring of these priority URLs in internal linking from regularly crawled pages (typically the homepage), along with submission to Google Search Console / Webmaster Tools, and perhaps sitemap submission.
The latter is not necessarily helpful in that sitemaps are often just as bloated as the sites they document. However, more recently some sites have found that having a specific sitemap for new URLs (often a news sitemap, but not necessarily) encouraged more rapid crawling of that sitemap specifically. This makes sense, given Google’s thirst for fresh URLs.
We’ve also seen the recent rise of indexing APIs from both Google and Bing. Google, at the time of writing, only provides this functionality for job listings (a vertical with particularly rampant crawl budget challenges), while Bing’s service, IndexNow, also supported by Yandex, provides wider support.
However, with some talk of CMS integration for new URLs triggering IndexNow requests, it’s difficult to see how this solution won’t eventually run into the exact same challenges — an oversupply of redundant URLs and little or no triage.
Try Moz Pro, free!
Technical activities with SEO intent
The last broad category of technical SEO for this chapter is not necessarily SEO at all - but rather, SEO-adjacent technical activities, with concrete SEO benefits.
Performance
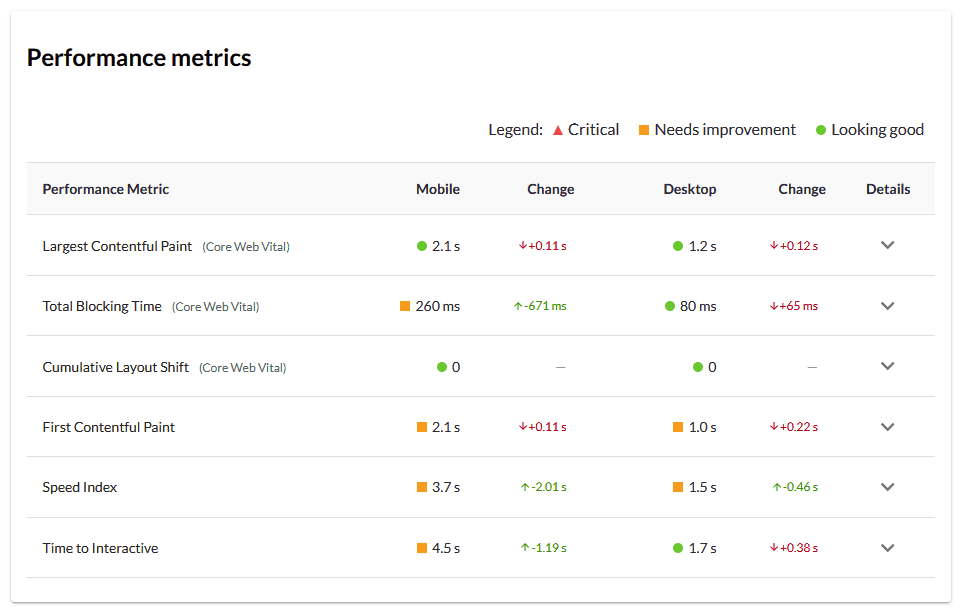
The most prominent of these in recent years has been performance, otherwise known as site speed. In August 2021 Google finally pushed through with its Page Experience update for mobile SERPs, which rewards sites for beating fixed thresholds for certain metrics. This set of metrics and thresholds is likely to be adjusted and expanded over time, and at the time of writing, desktop rollout is also imminent.
Web performance is a topic justifying a whole guide of its own, but SEOs should at least familiarize themselves with some of the key tools at their disposal.
Keep your site technically healthy with Moz Pro

Moz Pro automatically crawls your website and alerts you to new and urgent problems before they get out of hand. From duplicate content to missing canonicals to 404ing URLs and more, Moz Pro finds critical issues fast. Take it for a spin and see for yourself:
Browser dev tools
The chart grabbed from the network tab in Firefox browser dev tools shows a lot of useful information.
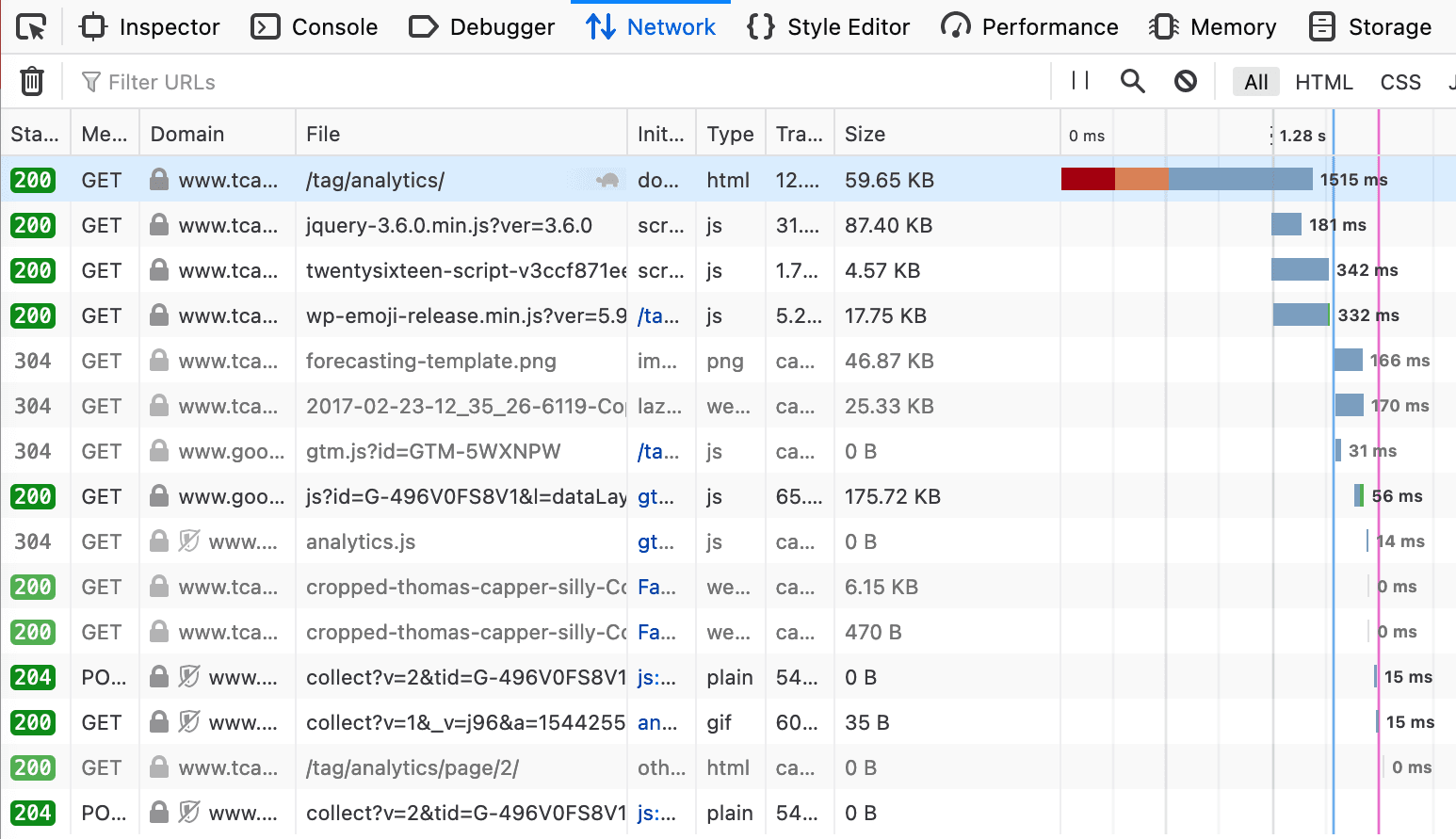
This screenshot shows the network tab in Firefox (press F12 in Chrome, then load the page you’re interested in).
You can see which resources have to be loaded before the DOM is ready (blue vertical line), and which then further delay the load of the page (pink/red line). By identifying which of these resources are redundant or slow, you can quickly find areas to focus on to improve site performance, or at least gain a greater understanding of how your page functions.
Chrome has similar functionality, but with another handy trick up its sleeve: it will actually tell you how much of each resource is required versus wasted code.

We can see, for example, that some resources which were delaying the load of the page are in fact almost totally unnecessary — a clear opportunity for improvement.
Specialist tools
Browser developer tools are very powerful, but can be something of a steep learning curve if not accompanied by other tools which offer a touch more direction.
Google’s own PageSpeed Insights does well in this niche, and of course is free to use. Better yet, our own Performance Metrics suite in Moz Pro provides all the same insights, but for more than one URL at a time, and with added tracking functionality and guidance.

Structured data
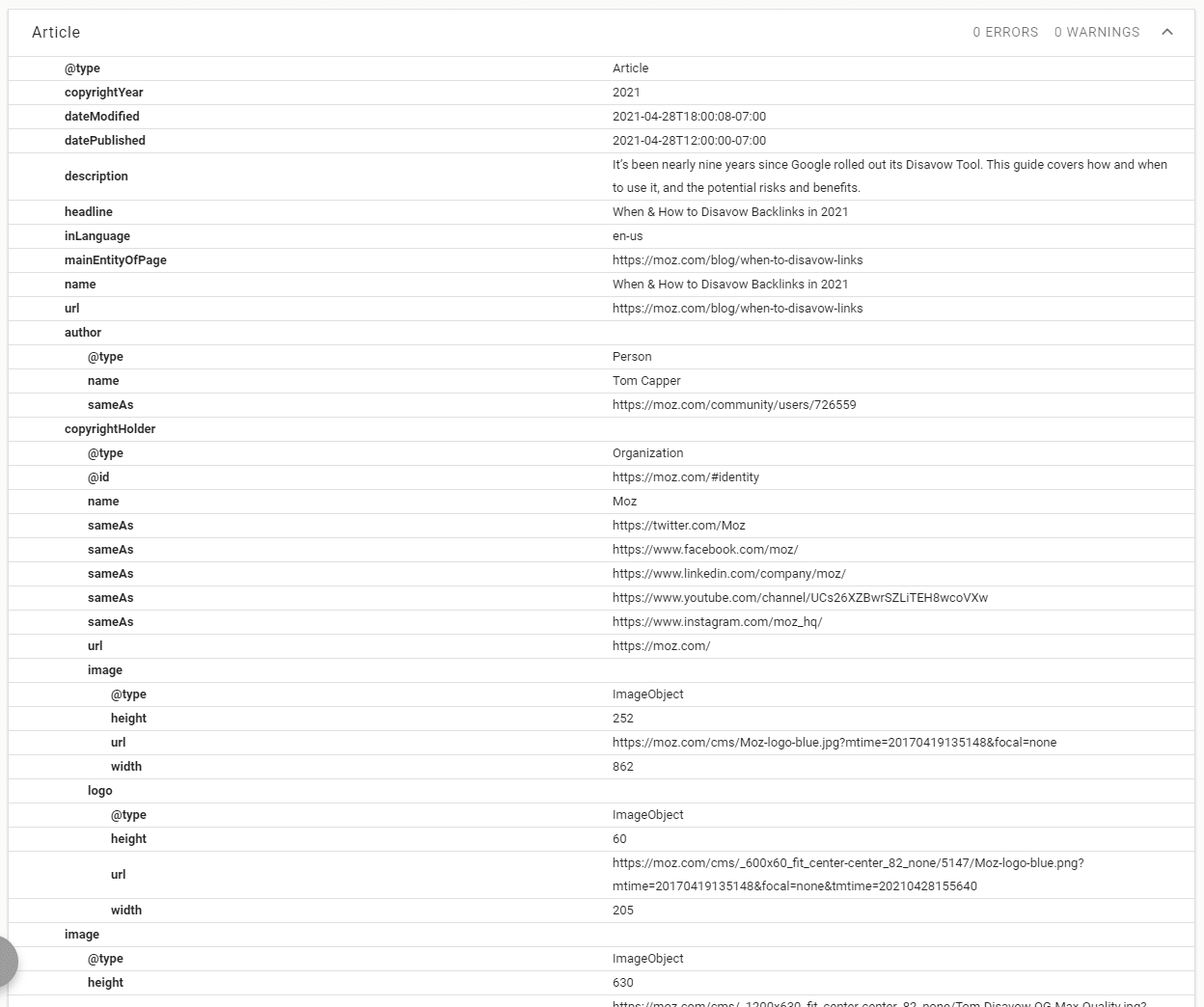
Structured data, in its simplest form, is a bunch of highly machine-readable information in the source code of a page. It is unarguably very useful to search engines. However, the usefulness to SEOs is more contested.
Some structured data has very clear SEO benefits, and this primarily means the structured data types associated with a Google search feature, such as star rating rich snippets, or recipe markup. You can read a more exhaustive list of these here.
More extensive markup aimed at simply providing extra information and context has less clear benefits, however. Split tests have repeatedly shown limited or only very situational benefit to such markup in terms of rankings and traffic.
Example: Aggregate ratings markup
One common objective for SEOs is having star ratings appear on their pages in Google Search Results. If your customers on average rate your product or service highly, this seems like a no-brainer in terms of attracting extra clicks.
You can see a bunch of code examples in Google’s documentation, which could even be injected via Google Tag Manager — so this shouldn’t be too hard, right?
There are in fact a few caveats:
Only certain content types are eligible for aggregate rating markup (although it does sometimes appear for types not in the official list).
Google has in the past penalized sites for applying universal rating markup to every page on their site. This is because structured data is supposed to apply to the page it's on, and the object of that page specifically, so should not describe your entire business on every page.
The reviews and ratings that your markup is describing should be clearly visible to users on that page
Incidentally, these are good principles for SEOs in general.
On the plus side, unlike with Google Ads, these reviews do not need to be from some verified third-party review aggregator — they can be from your own database, as long as the customers can see them.
So, if you have some database of reviews to work with, your steps might look like this:
Map indexed pages to customer reviews, so that reviews only apply to pages for the correct product or service, and no two pages have the same list of reviews
Display the aggregate rating and (some of) the relevant reviews on the corresponding pages
Inject markup via raw HTML or Google Tag Manager
Confirm via Google’s own Rich Results tool or via Google Search Console
SEO on the edge
The last topic for this chapter is an emerging tool in the technical SEO’s arsenal. The “edge” refers to servers at the edge of a network — potentially synonymous with a CDN, although not necessarily — that alter the page the server produces before it reaches the user.
This means that Edge SEO does not interfere at all with the original construction of the page, but instead is making on-the-fly changes to the page in transit.
Historically, if you want to make an SEO change to a website, you do it by either modifying the codebase of the site or by using the CMS (such as Wordpress, Drupal, etc).
Even before the rise of Edge SEO, though, some SEOs have advocated using Google Tag Manager as a “meta CMS” when the original site has become too old, complex, poorly maintained, or obsolete to maintain. While this is tempting it has a few obvious issues:
Even further increasing maintenance complexity
Requiring JavaScript rendering for Google to understand the changes
Render flash for users, if the changes are visible
Just putting off what is clearly a necessary rebuilding of the base website / institution
“Edge” SEO is often being used in a similar way, but avoids some of those drawbacks — there’s no JavaScript dependency, or accompanying render flash. In principle, almost any SEO change could be made at this level, depending on the complexity of the solution used — varying from “Edge workers” available on CDNs like Cloudflare, to dedicated standalone servers that sit between the original server and a CDN.
Next Up: Competitive SEO
How to rank in highly competitive niches.
This chapter was written by the ever-awesome Tom Capper, seasoned SEO and Senior Search Scientist at Moz.