
XML Sitemaps: The Most Misunderstood Tool in the SEO's Toolbox
The author's views are entirely his or her own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.
In all my years of SEO consulting, I’ve seen many clients with wild misconceptions about XML sitemaps. They’re a powerful tool, for sure — but like any power tool, a little training and background on how all the bits work goes a long ways.
Indexation
Probably the most common misconception is that the XML sitemap helps get your pages indexed. The first thing we’ve got to get straight is this: Google does not index your pages just because you asked nicely. Google indexes pages because (a) they found them and crawled them, and (b) they consider them good enough quality to be worth indexing. Pointing Google at a page and asking them to index it doesn’t really factor into it.
Having said that, it is important to note that by submitting an XML sitemap to Google Search Console, you’re giving Google a clue that you consider the pages in the XML sitemap to be good-quality search landing pages, worthy of indexation. But, it’s just a clue that the pages are important... like linking to a page from your main menu is.
Consistency
One of the most common mistakes I see clients make is to lack consistency in the messaging to Google about a given page. If you block a page in robots.txt and then include it in an XML sitemap, you’re being a tease. "Here, Google... a nice, juicy page you really ought to index," your sitemap says. But then your robots.txt takes it away. Same thing with meta robots: Don’t include a page in an XML sitemap and then set meta robots "noindex,follow."
While I’m at it, let me rant briefly about meta robots: "noindex" means don’t index the page. “Nofollow” means nothing about that page. It means "don’t follow the links outbound from that page," i.e. go ahead and flush all that link juice down the toilet. There’s probably some obscure reason out there for setting meta robots "noindex,nofollow," but it’s beyond me what that might be. If you want Google to not index a page, set meta robots to "noindex,follow."
OK, rant over…
In general, then, you want every page on your site to fall into two buckets:
- Utility pages (useful to users, but not anything you’d expect to be a search landing page)
- Yummy, high-quality search landing pages

Everything in bucket #1 should either be blocked by robots.txt or blocked via meta robots "noindex,follow" and should not be in an XML sitemap.
Everything in bucket #2 should not be blocked in robots.txt, should not have meta robots "noindex," and probably should be in an XML sitemap.
(Bucket image, prior to my decorating them, courtesy of Minnesota Historical Society on Flickr.)
Overall site quality
It would appear that Google is taking some measure of overall site quality, and using that site-wide metric to impact ranking — and I’m not talking about link juice here.
Think about this from Google’s perspective. Let’s say you’ve got one great page full of fabulous content that ticks all the boxes, from relevance to Panda to social media engagement. If Google sees your site as 1,000 pages of content, of which only 5–6 pages are like this one great page… well, if Google sends a user to one of those great pages, what’s the user experience going to be like if they click a link on that page and visit something else on your site? Chances are, they’re going to land on a page that sucks. It's bad UX. Why would they want to send a user to a site like that?
Google engineers certainly understand that every site has a certain number of "utility" pages that are useful to users, but not necessarily content-type pages that should be landing pages from search: pages for sharing content with others, replying to comments, logging in, retrieving a lost password, etc.
If your XML sitemap includes all of these pages, what are you communicating to Google? More or less that you have no clue as to what constitutes good content on your site and what doesn't.
Here’s the picture you want to paint for Google instead. Yes, we have a site here with 1,000 pages… and here are the 475 of those 1,000 that are our great content pages. You can ignore the others — they’re utility pages.
Now, let's say Google crawls those 475 pages, and with their metrics, decides that 175 of those are "A" grade, 200 are "B+," and 100 are "B" or "B-." That’s a pretty good overall average, and probably indicates a pretty solid site to send users to.
Contrast that with a site that submits all 1,000 pages via the XML sitemap. Now, Google looks at the 1,000 pages you say are good content, and sees over 50% are "D" or "F" pages. On average, your site is pretty sucky; Google probably doesn’t want to send users to a site like that.
The hidden fluff
Remember, Google is going to use what you submit in your XML sitemap as a clue to what's probably important on your site. But just because it's not in your XML sitemap doesn't necessarily mean that Google will ignore those pages. You could still have many thousands of pages with barely enough content and link equity to get them indexed, but really shouldn't be.
It's important to do a site: search to see all the pages that Google is indexing from your site in order to discover pages that you forgot about, and clean those out of that "average grade" Google is going to give your site by setting meta robots "noindex,follow" (or blocking in robots.txt). Generally, the weakest pages that still made the index are going to be listed last in a site: search.
Noindex vs. robots.txt
There’s an important but subtle difference between using meta robots and using robots.txt to prevent indexation of a page. Using meta robots "noindex,follow" allows the link equity going to that page to flow out to the pages it links to. If you block the page with robots.txt, you’re just flushing that down the toilet.
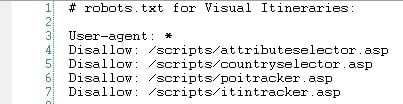
In the example above, I'm blocking pages that aren't real pages — they're tracking scripts — so I'm not losing link equity, as these pages DO NOT have the header with the main menu links, etc.

Think of a page like a Contact Us page, or a Privacy Policy page — probably linked to by every single page on your site via either the main menu or the footer menu. So there’s a ton of link juice going to those pages; do you just want to throw that away? Or would you rather let that link equity flow out to everything in your main menu? Easy question to answer, isn’t it?
Crawl bandwidth management
When might you actually want to use robots.txt instead? Perhaps if you’re having crawl bandwidth issues and Googlebot is spending lots of time fetching utility pages, only to discover meta robots "noindex,follow" in them and having to bail out. If you’ve got so many of these that Googlebot isn’t getting to your important pages, then you may have to block via robots.txt.
I’ve seen a number of clients see ranking improvements across the board by cleaning up their XML sitemaps and noindexing their utility pages:
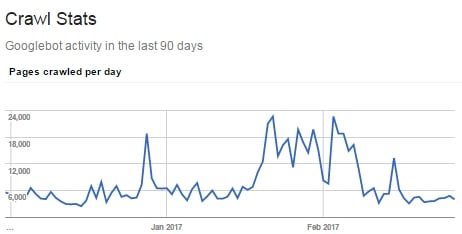
Do I really have 6,000 to 20,000 pages that need crawling daily? Or is Googlebot chasing reply-to-comment or share-via-email URLs?
FYI, if you’ve got a core set of pages where content changes regularly (like a blog, new products, or product category pages) and you’ve got a ton of pages (like single product pages) where it’d be nice if Google indexed them, but not at the expense of not re-crawling and indexing the core pages, you can submit the core pages in an XML sitemap to give Google a clue that you consider them more important than the ones that aren’t blocked, but aren’t in the sitemap.
Indexation problem debugging
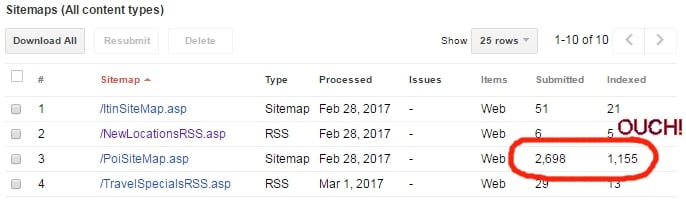
Here’s where the XML sitemap is really useful to SEOs: when you’re submitting a bunch of pages to Google for indexing, and only some of them are actually getting indexed. Google Search Console won’t tell you which pages they’re indexing, only an overall number indexed in each XML sitemap.
Let’s say you’re an e-commerce site and you have 100,000 product pages, 5,000 category pages, and 20,000 subcategory pages. You submit your XML sitemap of 125,000 pages, and find out that Google is indexing 87,000 of them. But which 87,000?
First off, your category and subcategory pages are probably ALL important search targets for you. I’d create a category-sitemap.xml and subcategory-sitemap.xml and submit those separately. You’re expecting to see near 100% indexation there — and if you’re not getting it, then you know you need to look at building out more content on those, increasing link juice to them, or both. You might discover something like product category or subcategory pages that aren’t getting indexed because they have only 1 product in them (or none at all) — in which case you probably want to set meta robots "noindex,follow" on those, and pull them from the XML sitemap.
Chances are, the problem lies in some of the 100,000 product pages — but which ones?
Start with a hypothesis, and split your product pages into different XML sitemaps to test those hypotheses. You can do several at once — nothing wrong with having a URL exist in multiple sitemaps.
You might start with 3 theories:
- Pages that don’t have a product image aren’t getting indexed
- Pages that have less than 200 words of unique description aren’t getting indexed
- Pages that don’t have comments/reviews aren’t getting indexed
Create an XML sitemap with a meaningful number of pages that fall into each of those categories. It doesn’t need to be all pages in that category — just enough that the sample size makes it reasonable to draw a conclusion based on the indexation. You might do 100 pages in each, for instance.
Your goal here is to use the overall percent indexation of any given sitemap to identify attributes of pages that are causing them to get indexed or not get indexed.
Once you know what the problem is, you can either modify the page content (or links to the pages), or noindex the pages. For example, you might have 20,000 of your 100,000 product pages where the product description is less than 50 words. If these aren’t big-traffic terms and you’re getting the descriptions from a manufacturer’s feed, it’s probably not worth your while to try and manually write additional 200 words of description for each of those 20,000 pages. You might as well set meta robots to "noindex,follow" for all pages with less than 50 words of product description, since Google isn’t going to index them anyway and they’re just bringing down your overall site quality rating. And don’t forget to remove those from your XML sitemap.
Dynamic XML sitemaps
Now you’re thinking, "OK, great, Michael. But now I’ve got to manually keep my XML sitemap in sync with my meta robots on all of my 100,000 pages," and that’s not likely to happen.
But there’s no need to do this manually. XML sitemaps don’t have to be static files. In fact, they don’t even need to have a .XML extension to submit them in Google Search Console.
Instead, set up rules logic for whether a page gets included in the XML sitemap or not, and use that same logic in the page itself to set meta robots index or noindex. That way, the moment that product description from the manufacturer’s feed gets updated by the manufacturer and goes from 42 words to 215 words, that page on your site magically shows up in the XML sitemap and gets its meta robots set to "index,follow."
On my travel website, I do this for a ton of different kinds of pages. I’m using classic ASP for those pages, so I have sitemaps like this:
When these sitemaps are fetched, instead of rendering an HTML page, the server-side code simply spits back the XML. This one iterates over a set of records from one of my database tables and spits out a record for each one that meets a certain criteria.
Video sitemaps
Oh, and what about those pesky video XML sitemaps? They're so 2015. Wistia doesn't even bother generating them anymore; you should just be using JSON-LD and schema.org/VideoObject markup in the page itself.
Summary
- Be consistent — if it’s blocked in robots.txt or by meta robots "noindex," then it better not be in your XML sitemap.
- Use your XML sitemaps as sleuthing tools to discover and eliminate indexation problems, and only let/ask Google to index the pages you know Google is going to want to index.
- If you’ve got a big site, use dynamic XML sitemaps — don’t try to manually keep all this in sync between robots.txt, meta robots, and the XML sitemaps.
Cornfield image courtesy of Robert Nunnally on Flickr.


![How We Increased Revenue with Speed Optimization [Local SEO Case Study]](png/analytics-2eba248_2021-04-15-235347cb22.png)
Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.