Strange Crawl Report
-
Hey Moz Squad,
So I have kind of strange case. My website locksmithplusinc.com has been around for a couple years. I have had all sorts of pages and blogs that have maybe ranked for a certain location a longtime ago and got deleted so I could speed up the site and consolidate my efforts. I said that because I think that might be part of the problem.
When I was crawl reporting my site just three weeks ago on moz I had over 23 crawl report issues. Duplicate pages, missing meta tags the regular stuff. But now all of a sudden when I crawl report on MOZ it comes up with Zero issues. So I did another crawl On google analytic and this is what came up.
SO im very confused because none of these url's are even url's on my site. So maybe people are searching for this stuff and clicking on broken links that are still indexed and getting this 404 error?
What do you guys think?
Thank you guys so much for taking a shot at this one.
-
The team from Giovatto is correct, you can click on the url and see where it is being linked from.
-
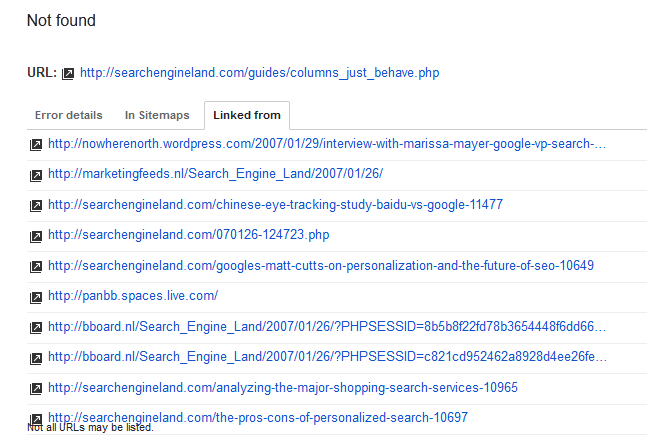
These are "Not Found" errors, meaning they are pages that do not exist but are being linked to somewhere on your site or another site.
If the page that is not found is a relevant page that holds a prominent ranking position, then by all means you probably want to either fix the broken link that was found or 301 redirect this broken URL to the correct URL.
You can check what page is linking to this broken URL by clicking the URL in the error report and switching to the "Linked From" tab and then decide if it's something that needs to be fixed.
{kind=link}
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Client suffered a malware attack. Removed links not being crawled by Google!
Hi all, My client suffered a malware attack a few weeks ago where an external site somehow created 700 plus links on my clients site with their content. I removed all of the content and redirected the pages to the home page. I then created a new temporary xml sitemap with those 700 links and submitted the sitemap to Google 9 days ago. Google has crawled the sitemap a few times but not the individual links. When I click on the crawl report for the sitemap in GSC, I see that the individual links still have the last crawled date from before they were removed. So in Googles eyes, that old malicioud content still exists. What do I do to ensure Google knows the contnt is gone and redirected? Thanks!
Technical SEO | | sk19900 -

My wepgages aren't crawled by google
Most of my webpages aren't crawled by google.
Technical SEO | | Poutokas
Why is that and what can i do to make google index at least most of my webpages?0 -

Bingbot appears to be crawling a large site extremely frequently?
Hi All! What constitutes a normal crawl rate for daily bingbot server requests for large sites? Are any of you noticing spikes in Bingbot crawl activity? I did find a "mildly" useful thread at Black Hat World containing this quote: "The reason BingBot seems to be terrorizing your site is because of your site's architecture; it has to be misaligned. If you are like most people, you paid no attention to setting up your website to avoid this glitch. In the article referenced by Oxonbeef, the author's issue was that he was engaging in dynamic linking, which pretty much put the BingBot in a constant loop. You may have the same type or similar issue particularly if you set up a WP blog without setting the parameters for noindex from the get go." However, my gut instinct says this isn't it and that it's more likely that someone or something is spoofing bingbot. I'd love to hear what you guys think! Dana
Technical SEO | | danatanseo1 -

Strange URL redirecting to my new site
Hi all, I recently relaunched a site on a brand new URL - www.boardwarehouse.co.uk. I've spent the last couple of weeks building some backlinks as well as developing a basic content strategy. We've started ranking for a few of our less competitive keywords which is great, however there's a strange site which either redirects or is mirroring our content. I'm at a complete loss as to what's causing this to happen and what i can do to stop it. On the attachment - my content is top and second. The fourth result is the offending site. Any help/ advice would be most helpful! Thanks in advance, Alick 0BSyNn6
Technical SEO | | Alick3000 -

New pages need to be crawled & indexed
Hi there, When you add pages to a site, do you need to re-generate an XML site map and re-submit to Google/Bing? I see the option in Google Webmaster Tools under the "fetch as Google tool" to submit individual pages for indexing, which I am doing right now. Thanks,
Technical SEO | | SSFCU
Sarah0 -

WOW My New Campaign Report is Impressive!!!
Have a look at this print screen. I move my store from osCommerce to BigCommerce. Lots of work, but diffenetly worth it I guess!!! 😉 bog32arkJ
Technical SEO | | BigBlaze2051 -

3 pages crawled?
For some reason, my account says it only crawled 3 pages this week, where its usually about 3K. This is my robots which shouldnt affect http://www.theprinterdepo.com/robots.txt and this is my site http://www.theprinterdepo.com any idea?
Technical SEO | | levalencia10 -

Crawling image folders / crawl allowance
We recently removed /img and /imgp from our robots.txt file thus allowing googlebot to crawl our image folders. Not sure why we had these blocked in the first place, but we opened them up in response to an email from Google Product Search about not being able to crawl images - which can/has hurt our traffic from Google Shopping. My question is: will allowing Google to crawl our image files eat up our 'crawl allowance'? We wouldn't want Google to not crawl/index certain pages, and ding our organic traffic, because more of our allotted crawl bandwidth is getting chewed up crawling image files. Outside of the non-detailed crawl stat graphs from Webmaster Tools, what's the best way to check how frequently/ deeply our site is getting crawled? Thanks all!
Technical SEO | | evoNick0